NVIDIA, yapay zeka alanında önemli bir kilometre taşı olarak Nemotron-CC adıyla geniş bir İngilizce AI eğitim veritabanını tanıttı. Bu yeni veritabanı, toplamda 6.3 trilyon token içeriyor ve bunun 1.9 trilyonu sentetik verilerden oluşuyor. Şirket, Nemotron-CC’nin, büyük dil modellerinin (LLM) eğitimi için geliştirilen en kapsamlı kaynaklardan biri olduğunu vurguladı. özellikle akademik ve ticari alanlarda bu yeniliğin önemli değişiklikler getireceği belirtiliyor. İşte konuyla ilgili detaylar…
NVIDIA, 6.3 trilyon tokenli yapay zeka eğitim veritabanı Nemotron-CC modelini tanıttı
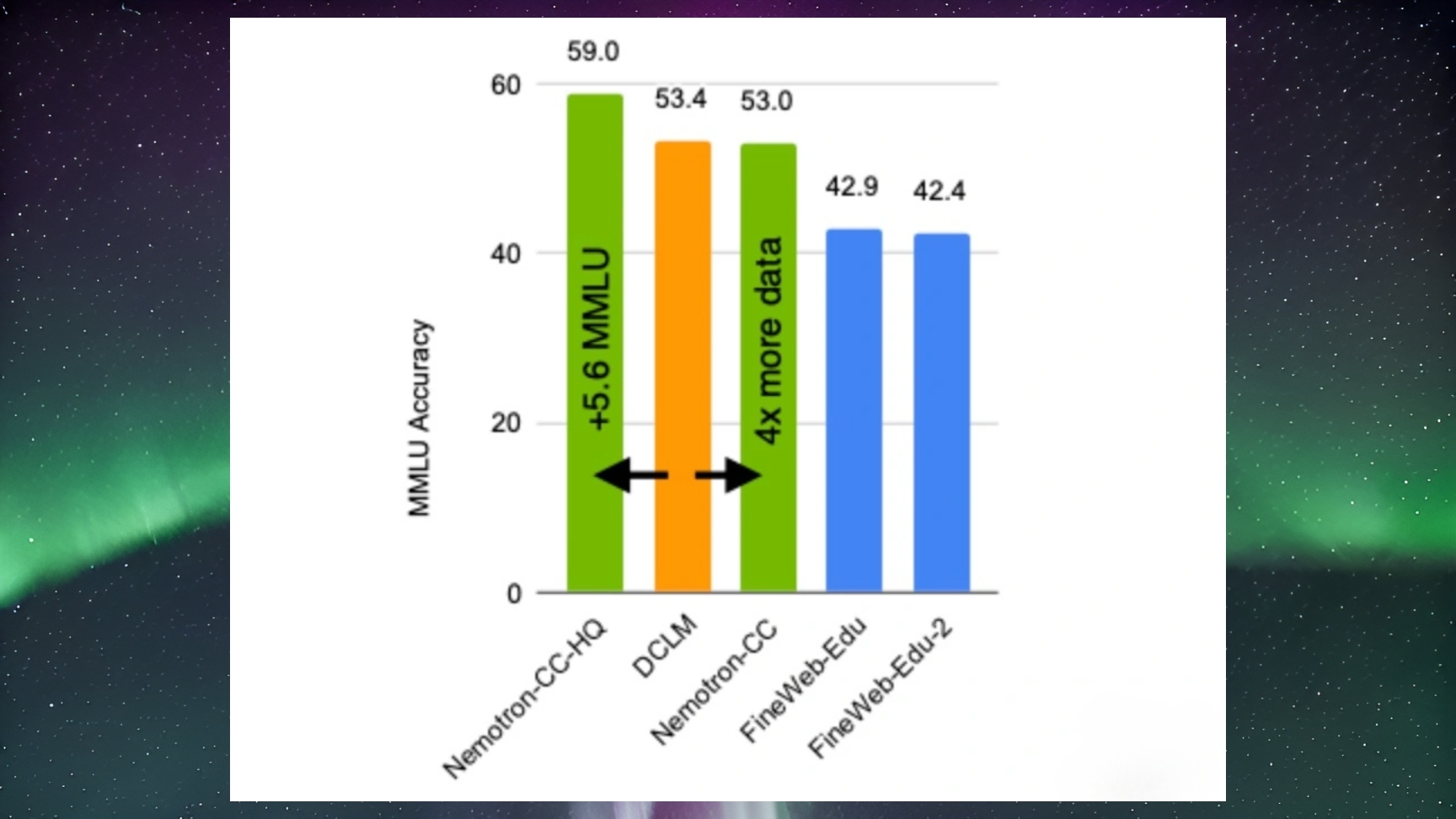
Nemotron-CC veritabanının geliştirilme aşamasında, Common Crawl platformundan toplanan büyük veriler kullanıldı. Bu veriler, detaylı bir işleme ve filtreleme sürecinden geçirilerek yüksek kaliteli bir alt küme olan Nemotron-CC-HQ üretildi. NVIDIA, bu veritabanının “büyük dil modelleri için mükemmel bir eğitim materyali” olarak işlev göreceğine inanıyor.